

IEEE Transactions on Robotics | 三维感知-复杂操作端到端机器人学习新方法
近日,中国科学院深圳先进技术研究院集成所智能仿生研究中心徐升团队与澳门大学杨志新团队合作,在机器人学习领域取得突破,提出了一种基于三维视觉融合注意力机制的端到端多模态模型——Fusion-Perception-to-Action Transformer(FP2AT)。该算法通过融合全局与局部体素网格特征,结合本体感知信息,显著提升了机器人在复杂三维场景中的精细操作能力。研究成果以“Fusion-Perception-to-Action Transformer: Enhancing Robotic Manipulation With 3-D Visual Fusion Attention and Proprioception”为题,发表于机器人领域顶级期刊IEEE Transactions on Robotics,论文第一作者为澳门大学-中国科学院深圳先进技术研究院联合培养博士生刘杨骏,徐升副研究员和杨志新副教授为共同通讯作者,先进院和澳门大学为共同第一单位。
研究背景:三维操作亟需“类人”感知与规划能力
传统机器人操作多依赖二维图像观测,难以捕捉三维空间中的物体结构、位置及姿态关系,导致精细化操作任务(如拔插、旋拧、堆叠)成功率低。虽然体素表示(Voxel Grid)能保留丰富的三维空间信息,但现有方法存在特征利用率低、动作预测分辨率不足等问题。人类在完成精细操作时,可通过灵活切换全局视野与局部聚焦,结合手部本体感知动态调整动作。受此启发,研究团队提出了一种“类人”的多模态感知到动作操作框架。
核心创新:基于三维视觉融合注意力机制的端到端多模态模型——Fusion-Perception-to-Action Transformer(FP2AT)(图2),其中具体包括:
1、设计全局-局部视觉融合注意力(HVFA-3D),模拟人类“先全局观察、再局部聚焦”的视觉感知模式,增强对关键操作区域的关注(图1)。
提出三维视觉互注意力机制(VMA-3D),实现跨尺度空间信息双向交互,提升场景理解能力。
2、集成关节力位、末端力/力矩、夹爪状态数据,感知接触力与运动状态,提升机器人对周围环境接触、本体运动和协调的感知能力。
渐进式动作预测框架,先通过低分辨率体素全局规划,再基于高分辨率局部体素微调动作,保持网络端到端特性的同时提升预测精度。
3、提出关键规划步数指标(ANKA),用于评估同类算法执行效率和规划能力。
实验结果:成功率提升,效率显著优化
研究团队在多个仿真(RLBench)和真实机械臂(UR5)任务上验证了FP2ATs的性能(视频),平均成功率较体素SOTA方法提升34.4%,较点云SOTA方法提升14.6%。展现出有更好的规划能力(如避障等),减少的关键规划步数。
应用前景:面向通用任务的智能机器人
该工作所提出的FP2AT理论具有强泛化性能,能够适配不同机器人操作平台,通过多模态感知与智能操作规划,引导机器人完成多样化复杂操作任务。该工作是团队在学习控制领域的进一步拓展,将来可与具身智能、人形机器人相结合,应用于家庭服务、医疗护理、工业生产、化学试验等各类场景。
研究资助
本研究在国家自然科学基金面上项目、澳门科技发展基金、广东省、深圳市、澳门大学等科技项目资助下完成。

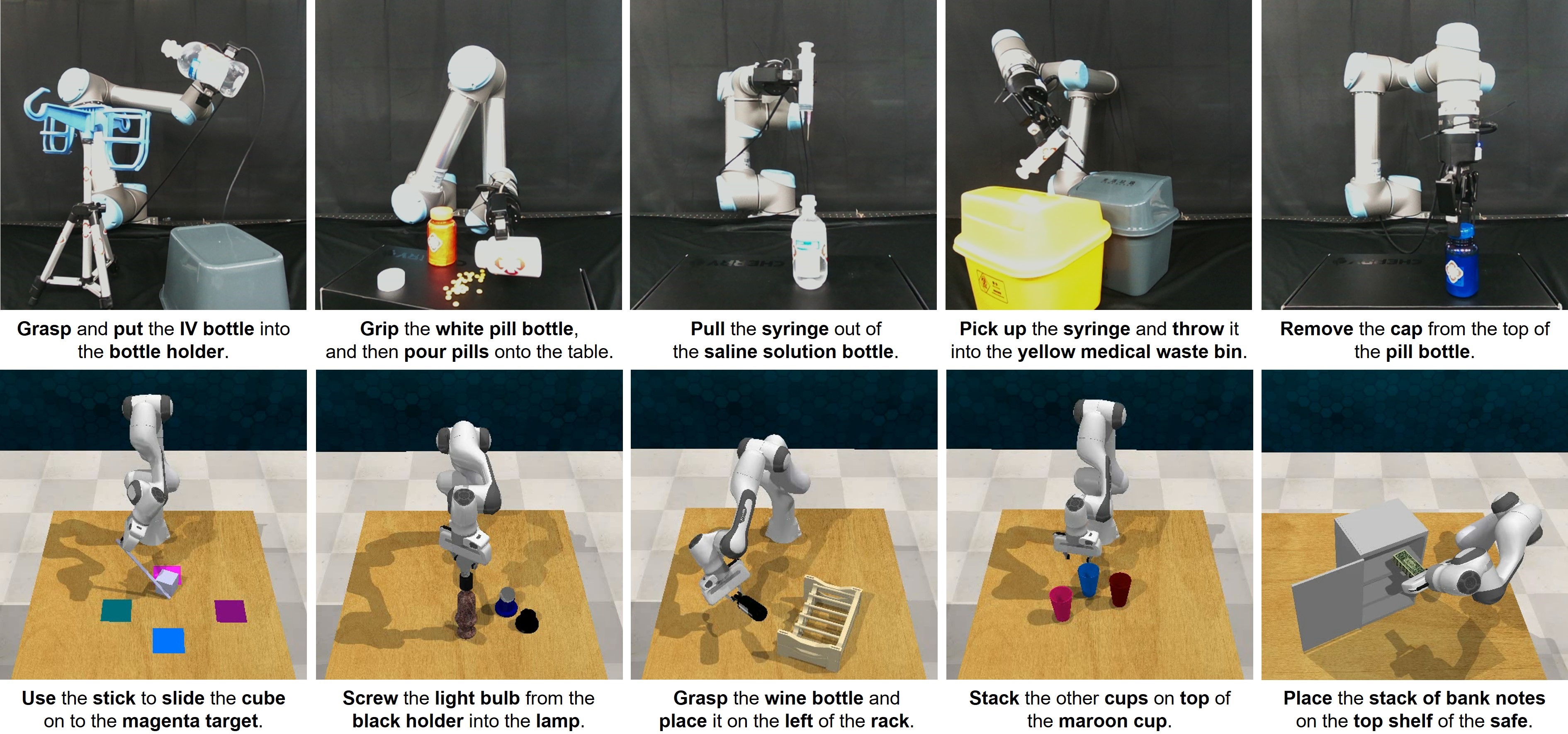
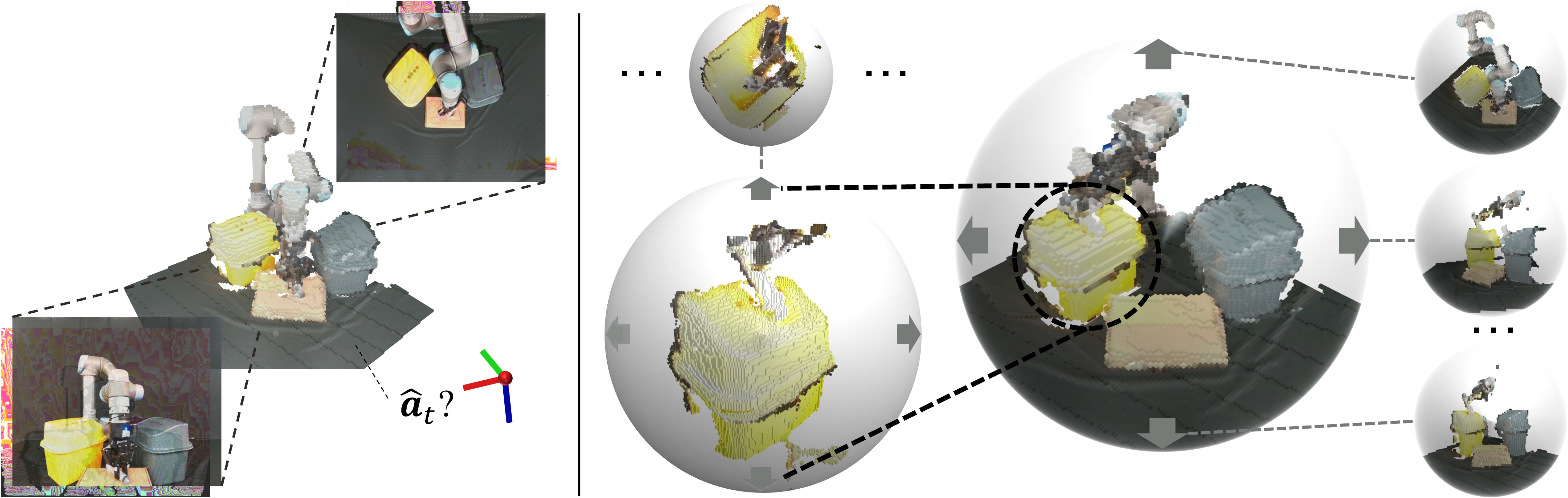
图1 | 体素重建与“类人”视觉感知
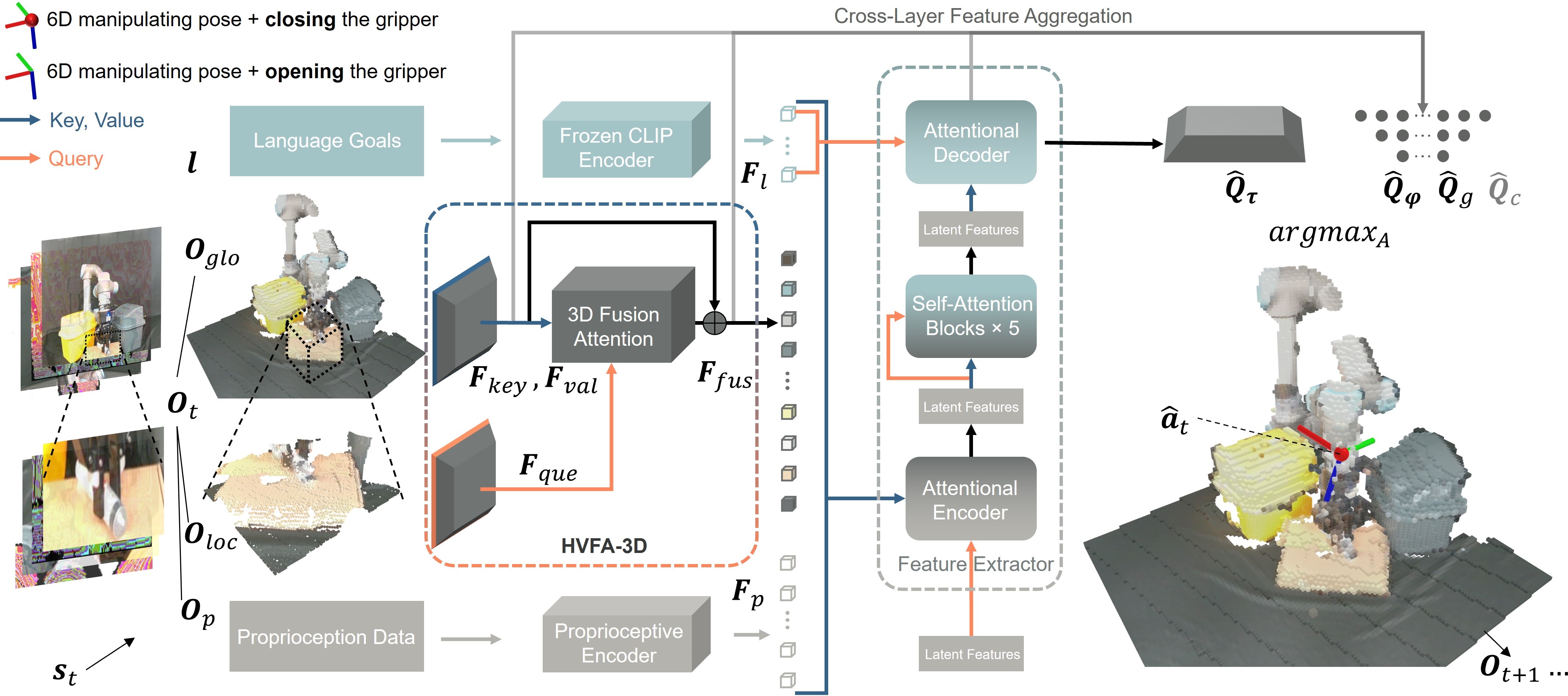
图2 | Fusion-Perception-to-Action Transformer网络架构

图3 | 面向家庭及医疗服务的仿真及实际实验验证
